
Un Análisis Profundo en la Industria Alimenticia con Python y Machine Learning
Un caso de estudio fascinante sobre cómo abordamos los desafíos de eficiencia en una línea de envasado dentro de la industria alimenticia. Los resultados iniciales nos mostraron un gran potencial de mejora, y las soluciones basadas en datos fueron clave.
Sebastian Cordero
5/8/20243 min read
Liderazgo, Mantenimiento, Resultados
.
📊 Análisis Inicial: ¿Dónde estábamos?
Nuestra línea operaba en 3 turnos de 8h (15 días, 360h), enfrentando métricas que indicaban oportunidades claras de optimización:
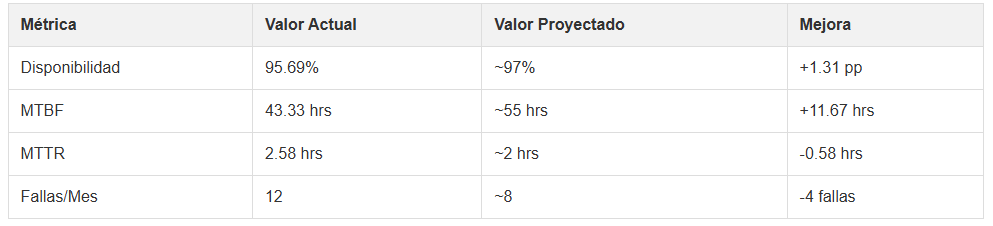
Disponibilidad: 95.69% (buena, pero con margen para alcanzar el 98%).
MTBF (Tiempo Medio Entre Fallas): 43.33 horas (¡una falla cada ~2 días!).
MTTR (Tiempo Medio Para Reparar): 2.58 horas (aceptable, pero reducible).
Proyección: 12 fallas en 720 horas (1 mes), un riesgo constante de paradas.
Estas cifras nos indicaron que necesitábamos una estrategia proactiva para minimizar interrupciones y maximizar la producción.
🛠️ Soluciones Propuestas y su Implementación con Python
Nos enfocamos en tres pilares fundamentales, apoyándonos en la capacidad analítica de Python:
1. Mantenimiento Predictivo con Machine Learning
Problema: Las 6 fallas en 15 días sugerían patrones que podíamos predecir.
Solución: Implementamos un modelo de Machine Learning (Random Forest) en Python para analizar los Tiempos Entre Fallas (TBF) y correlacionarlos con variables operativas (temperatura, velocidad, desgaste).
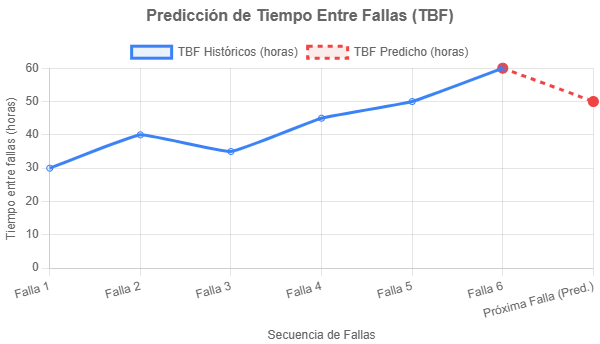
Insight Clave (Visualización): Un gráfico de líneas nos mostró la tendencia de los TBF históricos y, lo más importante, predijo el próximo tiempo entre fallas estimado en ~50.00 horas. Esto nos permite programar intervenciones antes de que la falla ocurra.
Impacto Esperado: Reducir fallas en un 20-30%, aumentando el MTBF a ~55 horas.
Gráfico: TBF históricos vs. TBF predicho para la línea de envasado.
2. Reducción del MTTR (Tiempo Medio Para Reparar) con Estandarización
Problema: El MTTR de 2.58 horas podía ser más bajo.
Solución: Estandarizamos procedimientos de reparación y usamos Python para identificar las causas de falla que consumían más tiempo.
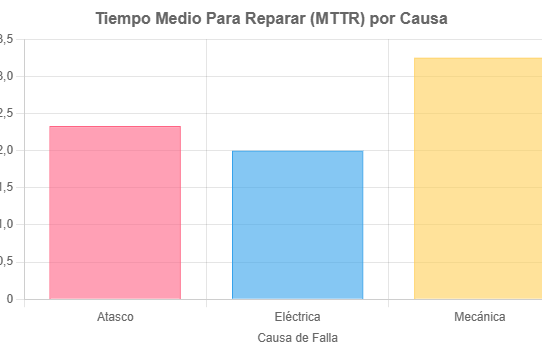
Insight Clave (Visualización): Un gráfico de barras reveló que las fallas mecánicas eran las que más tiempo tomaban (3.25 horas), en comparación con atascos (2.33h) o problemas eléctricos (2.00h). Esto nos permitió enfocar la capacitación y la disponibilidad de repuestos.
Acción: Capacitar al equipo en reparaciones mecánicas y asegurar repuestos críticos.
Impacto Esperado: Reducir el MTTR a ~2 horas, aumentando la disponibilidad a 96.5%.
Gráfico: MTTR por causa de falla en la línea de envasado
3. Optimización del Mantenimiento Preventivo
Problema: Mejorar la disponibilidad reduciendo paradas no planificadas.
Solución: Programamos mantenimientos preventivos basados en el 80% del MTBF promedio.
Resultado: Determinamos que el mantenimiento debe programarse cada 34.67 horas (~1.5 días). Esto proyecta una reducción de fallas de 6 a 4.20 en 15 días.
Impacto Esperado: Menos fallas (de 12 a ~8 en 1 mes), aumentando la disponibilidad a 97%.
📈 Impacto Global de las Soluciones
La implementación combinada de estas estrategias promete una mejora significativa en el rendimiento de la línea:
tabla con soluciones globales
✨ Conclusión y Llamada a la Acción
La integración de análisis de datos y Machine Learning en las estrategias de mantenimiento no solo mejora la eficiencia operativa, sino que también transforma la toma de decisiones, pasando de ser reactiva a predictiva.
¿Aplicas estas estrategias en tu industria? ¿Qué desafíos has encontrado o qué éxitos has logrado? ¡Me encantaría leer tus comentarios y experiencias!
Address
Del Viso, Pilar
Buenos Aires, Argentina